Top 50 Monitoring and Observality Interview Questions and Answers

1. What is monitoring?
Monitoring is the regular observation and recording of activities taking place in a project or system. It involves collecting data on various metrics to ensure the system operates correctly.
2. What is observability?
Observability refers to the capability of the system to allow insight into its internal state based on the outputs (logs, metrics, and traces) it produces.
3. What are the primary components of observability?
The primary components are logs, metrics, and traces.
4. What is the difference between monitoring and observability?
Monitoring is about collecting and analyzing predefined metrics and logs to ensure system health. Observability is broader, focusing on understanding the internal state of the system through its outputs, enabling more dynamic and proactive insights.
5. What are metrics in monitoring?
Metrics are quantitative data points collected over time to measure the performance of a system, such as CPU usage, memory usage, and request rates.
6. What are logs in monitoring?
Logs are records of discrete events that happen over time within a system. They provide detailed information about system behavior and errors.
7. How do you differentiate between structured and unstructured logs?
Structured logs are logs with a consistent and predictable format, often in JSON. Unstructured logs are free-form and can vary in format, making them harder to parse and analyze.
8. What is a service-level agreement (SLA)?
An SLA is a contract between a service provider and a customer that defines the level of service expected, including uptime, performance benchmarks, and issue resolution times.
9. What is distributed tracing?
Distributed tracing is a method used to monitor applications built on a microservices architecture. It tracks requests as they move through various services, helping to identify where failures or performance bottlenecks occur.
10. How does a trace differ from a log?
A trace provides a sequence of events or spans that track the lifecycle of a request as it traverses multiple services. Logs are discrete events recorded in a system.
11. What is a span in distributed tracing?
A span represents a single operation within a trace, including metadata such as start time, duration, and any associated tags or annotations.
12. What are some popular monitoring tools?
Prometheus, Grafana, Nagios, Zabbix, and Datadog are popular monitoring tools.
13. What are some popular observability tools?
Jaeger, Zipkin, New Relic, Splunk, and Elastic Stack (ELK) are popular observability tools.
14. What is Prometheus, and how does it work?
Prometheus is an open-source monitoring and alerting toolkit. It collects and stores metrics as time series data, providing powerful querying and alerting capabilities.
15. What is Grafana, and how does it work?
Grafana is an open-source platform for monitoring and observability. It provides interactive visualizations and dashboards for your metrics and logs data.
16. What is the ELK stack?
The ELK stack consists of Elasticsearch, Logstash, and Kibana. It is used for searching, analyzing, and visualizing log data in real time.
17. What are some best practices for logging?
Ensure logs are structured, use appropriate log levels (e.g., INFO, WARN, ERROR), avoid logging sensitive information, and implement log rotation and retention policies.
18. What are some best practices for metrics collection?
Define key performance indicators (KPIs), use appropriate granularity, avoid excessive metrics collection to prevent overhead, and ensure proper aggregation and retention policies.
19. How do you handle alert fatigue?
Prioritize alerts based on severity, set appropriate thresholds, use deduplication and correlation techniques, and implement proper escalation policies.
20. What is the importance of setting up dashboards?
Dashboards provide real-time visibility into system performance, helping to quickly identify issues and trends, and make data-driven decisions.
21. What is the purpose of anomaly detection in monitoring?
Anomaly detection helps to identify unusual patterns or behaviors in the system that could indicate potential issues or security threats.
22. How does synthetic monitoring work?
Synthetic monitoring involves simulating user interactions with a system to test performance and functionality. It helps in identifying issues before they affect real users.
23. What is the role of machine learning in observability?
Machine learning can be used to analyze large volumes of observability data to identify patterns, predict failures, and automate root cause analysis.
24. What are SLOs and SLIs, and how do they relate to SLAs?
SLOs (Service Level Objectives) are specific goals for service performance, while SLIs (Service Level Indicators) are the metrics used to measure performance. They are both used to define and measure compliance with SLAs.
25. What is OpenTelemetry?
OpenTelemetry is an open-source project that provides a set of APIs, libraries, and agents for collecting distributed traces and metrics from applications.
26. How do you implement a monitoring strategy for a microservices architecture?
Use distributed tracing, ensure each service has its own metrics and logs, implement centralized logging and monitoring, and establish clear SLOs and SLIs.
27. What are some challenges with monitoring cloud-native applications?
Dynamic and ephemeral nature of cloud resources, complexity of distributed systems, and the need for real-time observability across multiple services and platforms.
28. How do you ensure the scalability of your monitoring system?
Use distributed and scalable tools, implement proper data retention policies, and optimize the collection and storage of metrics and logs.
29. What is the role of AIOps in observability?
AIOps (Artificial Intelligence for IT Operations) uses AI and machine learning to enhance observability, automating tasks such as anomaly detection, root cause analysis, and predictive maintenance.
30. How can you use observability to improve incident response?
Observability provides detailed insights into system behavior, enabling faster identification and resolution of issues, and helps in post-incident analysis to prevent future occurrences.
31. How would you troubleshoot a performance issue in a web application?
Analyze metrics such as response times, CPU, and memory usage, check logs for errors or warnings, use distributed tracing to identify bottlenecks, and review recent changes or deployments.
32. How do you monitor the health of a database?
Track metrics such as query response times, connection counts, error rates, and resource usage (CPU, memory, disk I/O), and set up alerts for anomalies.
33. What steps would you take to investigate an increase in error rates?
Check logs for error messages, analyze recent changes in the code or infrastructure, use tracing to pinpoint where errors are occurring, and review metrics for related systems.
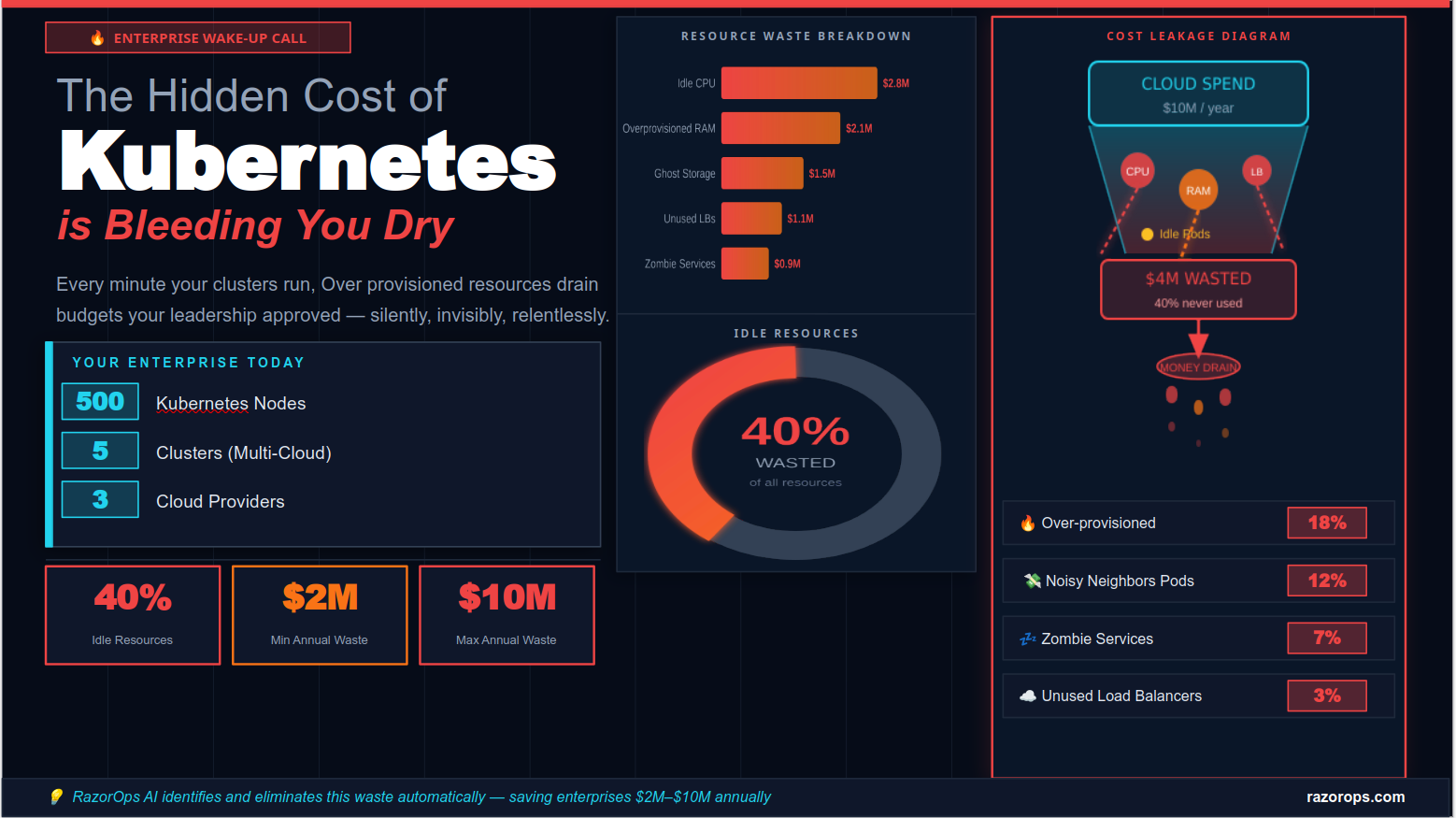
34. How would you set up monitoring for a Kubernetes cluster?
Use tools like Prometheus and Grafana for metrics, Fluentd or Elasticsearch for logs, Jaeger for tracing, and ensure monitoring covers nodes, pods, and application performance.
35. What are some common metrics to monitor in a web server?
Request rate, error rate, response time, CPU usage, memory usage, and disk I/O.
####
36. What are the differences between Prometheus and Nagios?
Prometheus is designed for metrics collection with powerful querying and alerting capabilities, while Nagios is primarily for host and service monitoring with a focus on alerting.
37. How do you integrate Prometheus with Grafana?
Add Prometheus as a data source in Grafana, then create and configure dashboards to visualize the collected metrics.
38. What is the role of Fluentd in the ELK stack?
Fluentd is used for log collection and forwarding, transforming log data before sending it to Elasticsearch for indexing and analysis.
39. How do you set up alerting in Prometheus?
Define alerting rules in Prometheus configuration, and use Alertmanager to handle and route alerts based on those rules.
40. What are the key features of Datadog?
Datadog offers real-time monitoring, log management, APM (Application Performance Monitoring), integrations with various tools and services, and advanced analytics and alerting.
####
41. What are the latest trends in observability?
Increased adoption of AIOps, use of OpenTelemetry for standardizing observability data, focus on real-time monitoring, and the integration of observability with CI/CD pipelines.
42. How is the shift to microservices affecting monitoring and observability?
It increases the complexity of monitoring due to the distributed nature of microservices, necessitating the use of distributed tracing, centralized logging, and comprehensive metrics collection.
43. What is the importance of real-time monitoring?
Real-time monitoring enables immediate detection and response to issues, minimizing downtime and ensuring better system performance and reliability.
44. How is AI/ML being used in monitoring and observability?
AI/ML is used for anomaly detection, predictive analytics, automating incident response, and enhancing the accuracy of root cause analysis.
45. What are some challenges in implementing effective observability?
Handling large volumes of data, ensuring data quality and consistency, integrating multiple tools,
46. How would you implement end-to-end observability in a CI/CD pipeline?
Integrate observability tools to collect logs, metrics, and traces during each phase of the CI/CD pipeline, automate the analysis of this data to detect issues early, and ensure feedback loops are in place for continuous improvement.
47. What are canary releases, and how do they relate to monitoring?
Canary releases involve deploying a new version of software to a small subset of users to monitor its performance and stability before rolling it out to the entire user base. Monitoring ensures any issues are detected and addressed promptly.
48. How do you ensure compliance and security in your monitoring setup?
Implement access controls, encrypt sensitive data, use compliant logging practices (such as GDPR for user data), and ensure regular audits and reviews of the monitoring setup.
49. What is the role of synthetic monitoring in proactive issue detection?
Synthetic monitoring simulates user interactions to test application performance and functionality. It helps detect issues before they impact real users by continuously checking system health and performance.
50. How can you use business metrics in observability?
Business metrics such as transaction volumes, user engagement, and revenue impact can be correlated with technical metrics to gain a holistic view of system performance and its impact on business outcomes.
51. Describe how you would handle a sudden spike in latency in your web application.
Investigate recent changes, analyze metrics for resource usage (CPU, memory, I/O), check for network issues, review logs for errors, use tracing to pinpoint latency sources, and potentially scale resources if needed.
52. How would you debug a failing microservice in a Kubernetes cluster?
Check the health and status of pods, analyze logs for errors, review resource usage, use tracing to understand service interactions, and inspect configuration files for misconfigurations.
53. What steps would you take to ensure high availability and reliability in a multi-cloud environment?
Implement redundant systems across clouds, use global load balancing, ensure consistent monitoring and alerting across environments, and regularly test failover mechanisms.
54. How do you monitor and optimize database performance?
Monitor key metrics like query response times, connection counts, and resource usage. Use indexing, query optimization, caching strategies, and regular maintenance tasks like vacuuming and analyzing.
55. Describe how you would implement a monitoring strategy for a containerized environment.
Use tools like Prometheus for metrics, Fluentd or ELK for logs, Jaeger for tracing, ensure each container is properly instrumented, and set up dashboards and alerts for real-time monitoring.
56. What metrics would you track to monitor the performance of a load balancer?
Track metrics such as request rate, response time, error rate, active connections, and resource utilization (CPU, memory).
57. How do you design effective alerts to minimize false positives and negatives?
Use appropriate thresholds, implement multi-condition alerts, use historical data to fine-tune alerting rules, and continuously review and adjust based on real-world outcomes.
58. What is the importance of anomaly detection in observability, and how is it implemented?
Anomaly detection helps identify unusual patterns that may indicate issues. It can be implemented using statistical methods, machine learning algorithms, and setting dynamic thresholds based on historical data.
59. How would you set up a dashboard to monitor application health?
Include key performance metrics (response times, error rates), resource usage (CPU, memory), service dependencies, and user engagement metrics. Use clear visualizations like graphs and charts for easy interpretation.
60. Explain the concept of alert correlation and its benefits.
Alert correlation involves linking related alerts to understand the root cause and reduce alert noise. It helps in prioritizing issues and speeding up the incident response process.
61. What are the challenges of log management in a distributed system?
Challenges include handling large volumes of log data, ensuring log consistency and completeness, managing log storage and retention, and correlating logs across different services.
62. How do you ensure the security and privacy of log data?
Implement encryption for log data at rest and in transit, use access controls to restrict log access, anonymize sensitive information, and follow compliance regulations for data retention and handling.
63. What strategies can be used to reduce log volume without losing critical information?
Use log sampling, filter out non-essential logs, aggregate logs, and implement log rotation and retention policies to manage storage.
64. Describe the process of log aggregation and its benefits.
Log aggregation involves collecting logs from multiple sources into a central repository for analysis. Benefits include easier troubleshooting, centralized management, and improved visibility into system behavior.
65. How do you implement log rotation and retention policies?
Set up policies to rotate logs based on size or time, archive or delete old logs based on retention requirements, and ensure automated scripts or tools are in place to manage this process.
66. How would you use observability data to perform root cause analysis?
Correlate logs, metrics, and traces to identify patterns and anomalies, use dashboards to visualize system performance, and drill down into specific events to pinpoint the cause of issues.
67. What steps would you take to mitigate a DDoS attack detected through monitoring?
Implement rate limiting, use DDoS protection services, scale resources to handle increased traffic, block malicious IP addresses, and communicate with stakeholders about the mitigation efforts.
68. How do you handle false positives in alerting systems?
Review and refine alert thresholds, use machine learning to improve accuracy, implement multi-condition alerts, and continuously monitor and adjust based on feedback and real-world data.
69. What is the role of a runbook in incident response, and how do you create one?
A runbook provides step-by-step procedures for handling incidents. Create one by documenting common issues, troubleshooting steps, escalation procedures, and contact information for relevant teams.
70. How do you ensure effective communication during an incident?
Establish clear communication channels, use incident management tools, provide regular updates to stakeholders, and conduct post-incident reviews to improve communication processes.
71. What are the benefits of real-time monitoring?
Immediate detection of issues, faster response times, improved system reliability, and the ability to proactively address potential problems before they impact users.
72. How do you implement real-time alerting in a monitoring system?
Use tools that support real-time data processing, set up alerts with low latency, ensure alerting rules are optimized for immediate detection, and integrate with incident management systems for quick response.
73. What is the importance of historical data in monitoring?
Historical data helps in identifying trends, establishing baselines, performing root cause analysis, and improving the accuracy of predictive models for future incidents.
74. How would you use machine learning for predictive monitoring?
Train models on historical data to identify patterns and anomalies, use these models to predict potential issues, and integrate with monitoring tools to trigger alerts based on predictions.
75. What is a heatmap, and how is it used in monitoring?
A heatmap is a graphical representation of data where values are represented by colors. In monitoring, it helps visualize the intensity of metrics over time or across different parts of the system, aiding in quick identification of hotspots or anomalies.
76. What trends are shaping the future of monitoring and observability?
Increased use of AI/ML for anomaly detection and predictive analytics, the adoption of OpenTelemetry for standardization, deeper integration with CI/CD pipelines, and enhanced focus on security and compliance.
77. How is the concept of observability evolving with serverless architectures?
Serverless architectures require more granular observability due to their ephemeral nature. Focus is shifting towards tracing and metrics that capture transient states and interactions.
78. What is the impact of edge computing on monitoring and observability?
Edge computing adds complexity to monitoring due to distributed data sources. It requires more localized and decentralized monitoring solutions, as well as the ability to aggregate and analyze data across different locations.
79. How do you foresee the role of AIOps in the future of observability?
AIOps will play a crucial role in automating monitoring processes, enhancing anomaly detection, providing intelligent root cause analysis, and enabling proactive incident management through predictive capabilities.
80. What innovations are expected in monitoring tools and platforms?
Innovations include enhanced real-time analytics, improved integration capabilities, more advanced AI/ML features, greater focus on user experience, and the development of more comprehensive and intuitive dashboards.
81. What are some common challenges in implementing a comprehensive monitoring strategy?
Challenges include managing the volume and variety of data, ensuring data quality, integrating multiple tools, handling dynamic and distributed environments, and maintaining scalability.
82. How do you address the challenge of monitoring in highly dynamic environments?
Use tools that support auto-discovery and dynamic scaling, implement centralized logging and monitoring, and ensure real-time data processing to keep up with changes.
83. What strategies can be used to ensure monitoring and observability cover all parts of a system?
Implement end-to-end monitoring, use a combination of metrics, logs, and traces, regularly review and update monitoring coverage, and ensure proper instrumentation of all system components.
84. How do you balance the trade-offs between detailed monitoring and system performance?
Optimize the frequency and granularity of data
Enjoyed this article? Share it.