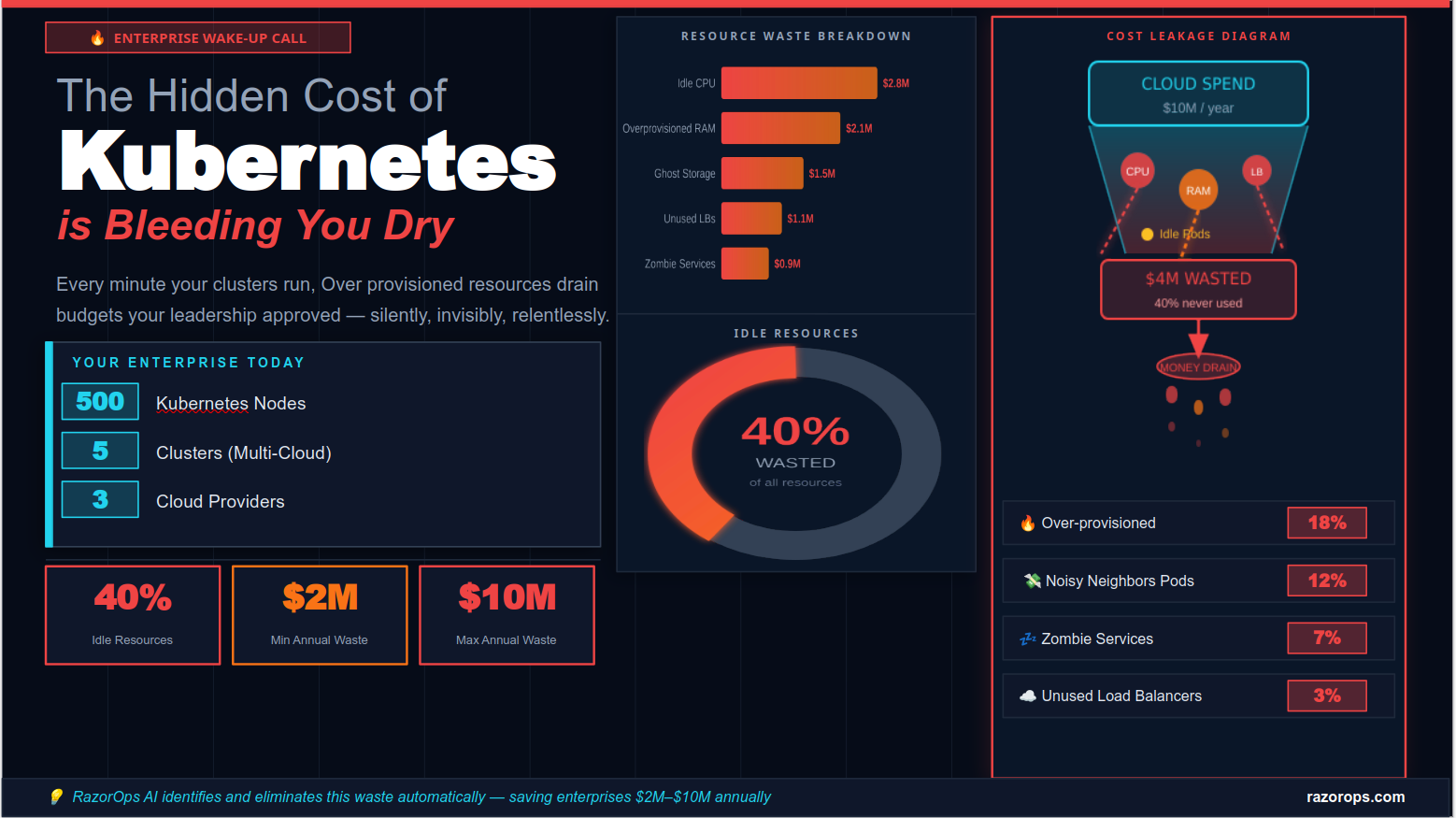
Effective Monitoring and Alerting Strategies in DevOps
DevOps teams play a crucial role in ensuring the continuous delivery of software applications. One of the key pillars of DevOps success is implementing effective monitoring and alerting strategies. In this blog post, we will explore the importance of monitoring and alerting in DevOps, discuss best practices, and provide insights into building a robust monitoring ecosystem.
Why Monitoring and Alerting Matter in DevOps:
Effective monitoring and alerting are essential for several reasons:
-
Early Detection of Issues: Monitoring allows teams to detect issues and performance bottlenecks early, preventing them from escalating into major problems.
-
Improved Mean Time to Resolution (MTTR): Swift alerting and response lead to faster issue resolution, minimizing downtime and improving overall system reliability.
-
Optimizing Performance: Monitoring helps identify areas for optimization, leading to enhanced application performance and user experience.
-
Data-Driven Decision Making: Monitoring data provides valuable insights for making data-driven decisions and continuous improvements.
Key Components of Monitoring and Alerting Strategy:
-
Infrastructure Monitoring: Monitor infrastructure components such as servers, networks, and databases to ensure they are performing optimally.
-
Application Monitoring: Track application metrics like response times, error rates, and resource utilization to identify performance bottlenecks.
-
Logs and Event Monitoring: Analyze logs and events to detect anomalies, troubleshoot issues, and gain visibility into system behavior.
-
User Experience Monitoring: Monitor user interactions to understand application usability and address user-facing issues proactively.
-
Security Monitoring: Implement security monitoring to detect and respond to security threats promptly.
Best Practices for Effective Monitoring and Alerting:
-
Define Clear Objectives: Clearly define monitoring objectives, metrics, and thresholds based on business requirements and user expectations.
-
Use Monitoring Tools: Utilize modern monitoring tools like Prometheus, Grafana, to collect and visualize data effectively.
-
Automate Alerts: Set up automated alerting based on predefined thresholds to notify teams about issues promptly.
-
Implement Escalation Policies: Define escalation policies to ensure alerts are routed to the right team members for timely resolution.
-
Continuous Improvement: Regularly review and refine monitoring strategies based on feedback, evolving requirements, and technology advancements.
-
Collaboration: Foster collaboration between development, operations, and security teams to align monitoring efforts with overall business goals.
-
Automated Alerts: Alerting mechanisms play a crucial role in notifying teams about anomalies, performance degradation, or critical events. By setting up automated alerts based on predefined thresholds and conditions, DevOps teams can respond swiftly to issues, minimize downtime, and ensure a seamless user experience.
-
Scalability and Flexibility: Monitoring and alerting solutions should be scalable and flexible to adapt to evolving infrastructure needs. Whether you’re managing a small application or a complex microservices architecture, the ability to scale monitoring capabilities and customize alerting rules is essential for maintaining operational efficiency.
-
Integration with DevOps Tools: Seamless integration with DevOps tools such as CI/CD pipelines, configuration management, and incident management platforms enhances collaboration and streamlines workflows. Integrating monitoring and alerting into the DevOps toolchain enables automated responses, rapid issue resolution, and continuous improvement.
-
Predictive Analytics: Leveraging predictive analytics and machine learning algorithms can enhance monitoring capabilities by identifying patterns, predicting potential issues, and recommending proactive measures. By anticipating problems before they occur, DevOps teams can prevent downtime, optimize resource utilization, and improve overall system reliability.
-
Continuous Improvement: Monitoring and alerting strategies should be continuously refined based on feedback, performance metrics, and industry best practices. Adopting a culture of continuous improvement ensures that DevOps teams stay ahead of emerging challenges, optimize operational processes, and deliver exceptional value to stakeholders.
-
Security Monitoring: In today’s cybersecurity landscape, incorporating security monitoring into DevOps practices is imperative. Monitoring for security threats, vulnerabilities, and compliance issues helps mitigate risks, protect sensitive data, and ensure regulatory compliance.
By implementing effective monitoring and alerting strategies in DevOps, organizations can achieve operational excellence, improve system reliability, accelerate time-to-market, and deliver superior user experiences. Embracing a proactive approach to monitoring not only enhances performance but also fosters a culture of collaboration, innovation, and continuous improvement across development and operations teams. Follow RazorOps Linkedin Page Razorops, Inc.
Enjoyed this article? Share it.