Kubernetes Autoscaling for Continuous Integration/Continuous Deployment

Continuous Integration/Continuous Deployment (CI/CD), the ability to adapt swiftly to fluctuating workloads is paramount. Kubernetes, with its dynamic orchestration capabilities, offers an invaluable toolset for achieving seamless scalability. This article explores the concept of Kubernetes autoscaling and its pivotal role in optimising CI/CD pipelines. We’ll delve into strategies, best practices, and real-world examples to empower teams in their quest for reliable and efficient application releases.
Understanding Kubernetes Autoscaling:
-
Unpacking Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA).
-
How Cluster Autoscaler balances resources across nodes.
Dynamic Scaling for CI/CD Workloads:
-
Tailoring autoscaling to suit the demands of CI/CD pipelines.
-
Identifying key performance metrics for efficient autoscaling decisions.
Implementing Auto Scaling Metrics and Policies:
-
Setting up custom metrics for precise auto scaling triggers.
-
Defining scaling policies to align with specific workload requirements.
Fine-tuning Auto Scaling Parameters:
-
Strategies for adjusting scaling thresholds and intervals.
-
Balancing responsiveness with stability for optimal performance.
Autoscaling Beyond Pods: Services, Deployments, and More:
-
Extending auto scaling capabilities to other Kubernetes resources.
-
Ensuring seamless scaling for complex applications.
Auto Scaling in Multi Tenant Environments:
-
Managing resource contention and isolation in shared Kubernetes clusters.
-
Strategies for fair and efficient auto scaling across diverse workloads.
Avoiding Pitfalls: Common Challenges and Solutions:
-
Addressing potential issues with autoscaling, such as noisy neighbours and resource contention.
-
Implementing safeguards to prevent over-scaling or under-scaling.
Real-world Examples and Best Practices:
-
Case studies showcasing successful implementation of Kubernetes autoscaling in CI/CD pipelines.
-
Lessons learned and actionable takeaways for similar deployments.
Monitoring and Debugging Autoscaling Events:
-
Leveraging Kubernetes monitoring tools to gain insights into autoscaling events.
-
Troubleshooting common issues and optimising autoscaling configurations.
Future Trends and Innovations in Kubernetes Autoscaling:
-
Exploring emerging technologies and practices shaping the future of autoscaling.
-
Predictions and recommendations for staying ahead in the CI/CD landscape.
With Kubernetes autoscaling as a cornerstone of CI/CD strategies, teams can achieve a new level of efficiency and reliability in their application release processes. By mastering the intricacies of dynamic scaling, organisations can adapt to evolving workloads, ensuring that their deployments remain robust, responsive, and ready for whatever challenges lie ahead.
The Essence of Kubernetes Autoscaling
Kubernetes autoscaling operates on the principle of ensuring that your application has the resources it needs to handle incoming traffic and requests. Traditionally, scaling was a manual task, requiring developers to predict demand and provision resources accordingly. However, with Kubernetes autoscaling, this process becomes automated and responsive.
Horizontal Pod Autoscaling (HPA)
At the heart of Kubernetes autoscaling is Horizontal Pod Autoscaling (HPA), which adjusts the number of pods in a deployment based on observed CPU utilization or other custom metrics. When CPU usage surpasses a defined threshold, HPA instructs Kubernetes to add more pods to distribute the load. Conversely, during lulls in traffic, excess pods are automatically scaled down, ensuring optimal resource utilisation.
Vertical Pod Autoscaling (VPA)
In addition to HPA, Kubernetes offers Vertical Pod Autoscaling (VPA), which optimises resource allocation by adjusting the resource requests and limits of individual pods. By dynamically tuning CPU and memory allocations, VPA helps eliminate resource bottlenecks and improve overall application performance.
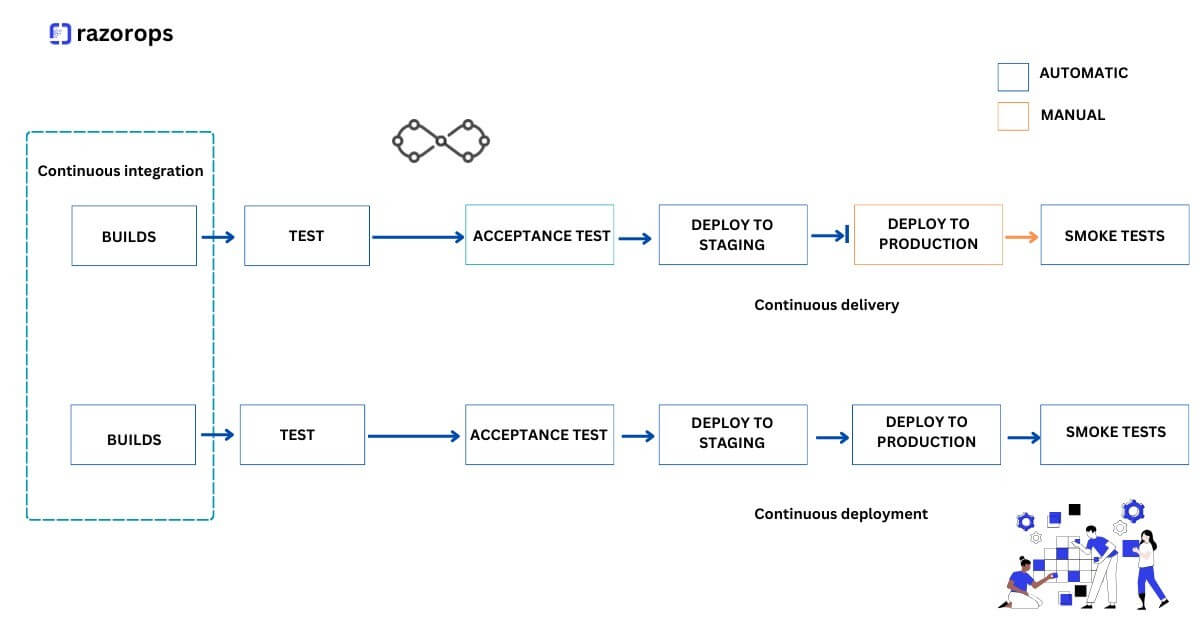
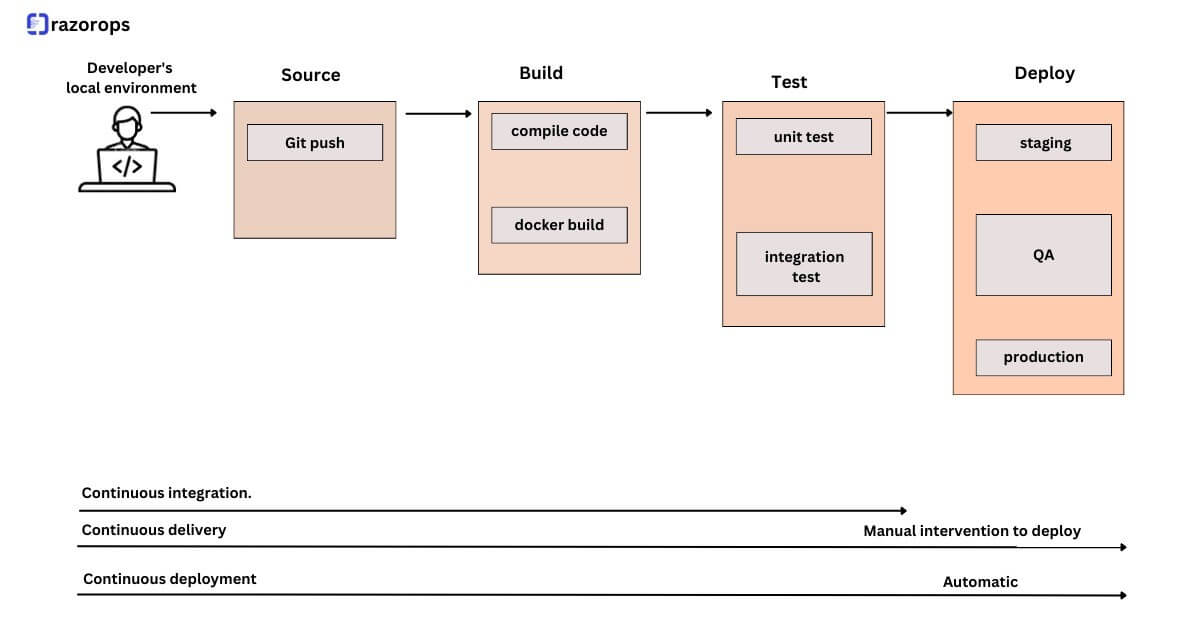
Seamless Integration with CI/CD Pipelines
When combined with CI/CD pipelines, Kubernetes autoscaling becomes a game-changer for development teams. CI/CD pipelines automate the building, testing, and deployment of applications, ensuring a swift and reliable release process.
By integrating autoscaling into this workflow, teams can achieve the following benefits:
1. Improved Resource Efficiency:
Autoscaling allows for precise resource allocation, preventing over-provisioning and reducing unnecessary costs. This ensures that resources are allocated only when needed, optimizing both performance and budget.
2. Enhanced Reliability:
With autoscaling, applications can dynamically respond to spikes in traffic, preventing instances of overload and ensuring consistent performance even under heavy loads. This enhances the overall reliability and availability of the application.
3. Seamless Scaling:
Autoscaling seamlessly adjusts resources without manual intervention. This means that as demand fluctuates, the infrastructure automatically adapts to maintain optimal performance, allowing development teams to focus on code rather than resource management.
Implementing autoscaling in any system, including Kubernetes, can bring significant benefits, but it also comes with its own set of challenges.
Here are some common challenges faced when implementing autoscaling:
Granularity of Scaling: Determining the right level of granularity for auto scaling can be tricky. Should you scale at the level of pods, containers, nodes, or even higher? This decision can impact the responsiveness and efficiency of the autoscaling system.
Metric Selection and Configuration: Choosing the right metrics to trigger auto scaling is crucial. It’s important to monitor relevant performance indicators (CPU usage, memory, network traffic, etc.) and set appropriate thresholds. Misconfigured metrics can lead to either over-scaling or under-scaling.
Latency in Scaling Decisions: There may be a delay between when a metric exceeds its threshold and when the autoscaler actually adds or removes resources. This latency can be problematic for applications with rapidly changing workloads.
Noisy Neighbour Problem: In a multi-tenant environment, one application’s behaviour can affect the performance of others on the same cluster. Autoscaling may need to take into account the overall load on the cluster to avoid inadvertently causing performance issues.
Pod Startup Time: The time it takes to start a new pod can be a significant factor in autoscaling. If pods take a long time to become ready, this can impact the responsiveness of the autoscaling system.
Scaling Down Safely: Scaling down too aggressively can lead to resource contention or even service disruptions. Implementing safeguards to ensure that removing resources won’t impact the overall stability of the system is crucial.
Stateful Applications: Autoscaling stateful applications introduces additional complexity. Ensuring that scaling doesn’t result in data loss or corruption is a critical consideration.
Cost Management: Autoscaling can lead to increased costs if not managed carefully. It’s important to weigh the benefits of increased availability and performance against the additional infrastructure costs.
Application-Specific Challenges: Some applications have unique requirements or constraints that may not align perfectly with auto scaling strategies. For example, applications with long initialization times or specialised hardware needs may require custom solutions.
Testing and Validation: Implementing auto scaling requires thorough testing to ensure that it behaves as expected under various conditions. This includes both performance testing and failure mode testing.
Dynamic Workload Patterns: Workloads that exhibit sudden spikes or sharp drops can pose challenges for auto scaling systems. Ensuring that the system can respond quickly and accurately to such changes is important.
Addressing these challenges requires careful planning, monitoring, and ongoing optimization. It’s important to iterate on autoscaling configurations and strategies as the system and its workload evolve over time Follow RazorOps Linkedin Page Razorops, Inc.